本文根据:http://www.chromium.org/developers/design-documents/gpu-accelerated-compositing-in-chrome 翻译
摘要
本文讲述了chrome中硬件加速合成(compositing[1])的实现
简介:为什么使用硬件进行合成(compositing)
传统方式下,浏览器依赖于CPU来渲染页面内容。而随着GPU硬件能力的不断发展(包括一些超小型设备的硬件能力也有很大提升),人们开始试图使用GPU的硬件能力来获得更好的性能和更少的电量消耗。使用GPU来渲染合成页面内容可以获得明显的速度的提升。
硬件合成有以下几个优点:
- GPU在合成页面layer上的效率要比CPU高很多,尤其是涉及大量像素的drawing[2]和compositing操作。当然,GPU设计出来本来就是做这些工作的。
- 对于已经存在GPU中的内容,回读代价太大且没有必要(比如视频加速, Canvas2D, 或者WebGL).
- 通过在CPU和GPU之间并行,可以在同一个时间操作,以此形成一个高效的图形管道。
Part 1:Blink Rending 基础
Blink Rending 引擎(由Google和Opera Software开发的浏览器排版引擎)的源码十分繁多和复杂。为更好理解在chrome中GPU加速是如何工作的,我们首先需要了解Blink引擎是如何渲染页面的。
Nodes和DOM树
在Blink引擎中,页面内容是存储为由Node对象组成的树状结构,也就是DOM树。每一个HTML element元素都有一个Node对象与之对应,DOM树的根节点永远都是Document Node。
从Nodes到RenderObjects
DOM树中得每个node节点都有一个对应的RenderObject。RenderObject存储在与DOM树相对应的树形结构中——Render Tree。RenderObject知道如何在屏幕上paint[3] Node内容,当然为实现这一操作,RenderObject会调用GraphicsContext来执行必要的draw[2]操作。其中,GraphicsContext就是负责将像素写入位图(bitmap)[4]中,这些位图最终会展示在屏幕上。
在老的实现方式下(不使用GPU),大部分GraphicsContext调用其实是去调用一个SkCanvas或者SkPlatformCanvas(Skia Graphics Library2D图形处理库的类)等等,将其paint进一个software bitmap中(参考这篇文章了解更多细节)。但是,现在painting不再放在主线程(main thread)(本文之后会讲到),这些命令现在会记录到一个SkPicture中。SkPicture是一个序列化的数据结构,它可以捕获调用命令并在之后重发这些命令,类似一个display list
从RenderObjects到RenderLayers
每一个RenderObject都直接或间接(通过其父对象)的同一个RenderLayer相关联。
一般来说,拥有相同的坐标空间(比如:受相同CSS transform影响的)的RenderObjects,属于同一个RenderLayer。RenderLayer的作用就是保证页面元素以正确的顺序合成(composited),这样才能正确的展示元素的重叠以及半透明元素等等。会有一些情形,为一些特殊的RenderObjects创建一个新的RenderLayer。以下是常见的一定会新建RenderLayer的RenderObject:
- 页面的根节点的RenderObject
- 有明确的CSS定位属性(relative,absolute或者transform)
- 是透明的
- 有CSS overflow、CSS alpha遮罩(alpha mash)或者CSS reflection
- 有CSS 滤镜(fliter)
- 3D环境或者2D加速环境的canvas元素对应的RenderObject
- video元素对应的RenderObject
值得注意的是,RenderObject同RenderLayer并不是一对一的。对于上述特殊的RenderObjects,它对应于为它所创建的新的RenderLayer,而其他的RenderObjects,对应于其第一个拥有RenderLayer的父RenderObject
RenderLayer也是一个树状的结构。根节点就是页面根元素所对应的RenderLayer,视觉上,每一个layer节点的后代都包含在父layer中。每一个RenderLayer的子layer保存在两个升序排列的列表中,分别是negZOrderList(负z-index的layers,即当前layer之下的layer)和posZOrderList(正z-index的layers,即当前layer之上的layer)
从RenderLayers到GraphicsLayers
为利用合成器(compositor),一些(不是全部)RenderLayers有独立的backing surface(有独立backing surface的layer被认为是合成层(compositing layers))。如果RenderLayer是一个合成层,那么它有属于它自己的单独的GraphicsLayer,否则它和它的第一个拥有GraphicsLayer的父layer共用一个GraphicsLayer。如同RenderObject同Renderlayer的关系一样。
每一个GraphicsLayer都有一个GraphicsContext,其对应的RenderLayer会paint进GraphicsContext中。合成器(compositor)最终会负责,将由GraphicsContext输出的位图(bitmap[4])合并成最终屏幕显示的图案。
虽然,在理论上,每一个独立的RenderLayer都可以paint进一个独立的backing surface中(拥有自己独立的backing surface,成为独立的合成层),但是,实际上,这样做十分消耗显存。在当前的Blink引擎的实现中,只有在如下的场景中,RenderLayer会是独立的合成层:
- 有3D或者perspective transform的CSS属性的层
- 使用加速视频解码的video元素的层
- 3D或者加速2D环境下的canvas元素的层
- 插件,比如flash(Layer is used for a composited plugin)
- 对opacity和transform应用了CSS动画的层
- 使用了加速CSS滤镜(filters)的层
- 有合成层后代的层
- 同合成层重叠,且在该合成层上面(z-index)渲染的层
层压缩(Layer Squashing)
所有的规则都会有漏洞。正如上面提到的,GraphicsLayers会消耗内存和其他资源(比如一些饱受争议的操作,随着GraphicsLayer树的大小增长,会使CPU执行时间越来越长)。当一些RenderLayer同一个有着独立backing surface的RenderLayer重叠时,就会产生大量的额外的层,十分消耗资源。
我们把产生合成层的自身原因(比如有3D变换的层)称之为直接原因(direct compositing reasons)。为了防止上述所说的“层爆炸”,当很多element覆盖在因直接原因产生的层之上时,Blink引擎,会将这些element的RenderLayers覆盖在“direct compositing reason”的RenderLayer上,同时将他们压缩(squash)成单一的一个backing store。这就防止了由覆盖引起的层爆炸。更多细节请看这里和这里
从GraphicsLayers到WebLayers再到CC Layers
chrome在 src/webkit/renderer/compositor_bindings中实现了WebLayer的接口。通过WebLayer和cc layer(chrome compositor layer)实现GraphicsLayers。
The compositing Forest
总的来说,为rendering服务的有如下四种树形结构:
- DOM Tree,基本的模型
- RenderObject Tree,同DOM树的可见节点是一一对应的。RenderObject知道如何去paint其相对应的DOM节点
- RenderLayer Tree,由RenderLayers组成,这些RenderLayer对应于RenderObject树的RenderObject。这种对应关系是一对多的。
- GraphicsLayer Tree,由GraphicsLayers组成,这些GraphicsLayer对应于RenderLayer树的RenderLayer。这种对应关系是一对多的。
如下图所示: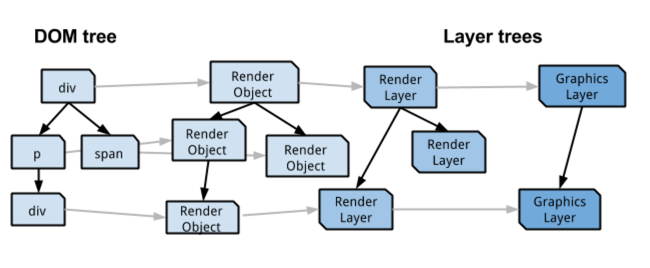
之后文章中所说的层(layer)都代指cc layer(chrome compositor layer:GraphicsLayer在chrome中得实现)。合成器(Compositor)操作的是cc layer。
Part 2:The Compositor(合成器)
chrome合成器(Compositor)是一个软件库,用来管理GraphicsLayer树以及协调帧(frame)生命周期。代码在src/cc下。
Compositor介绍
回想一下,rendering有两个阶段:先是paint然后composite。合成器会在每个合成层(per-compositing-layer)的基础上执行一些额外的工作。比如,在合成层的位图合成前,合成器会负责对这些合成层的位图执行一些必要的transform(比如层的CSS tranform属性指定的变换)。另外,因为层的painting和compositing解耦了,所以一个invalidating[6](需要repainting的)层只会重绘(repainting)自己的内容,然后所有层重新进行合成(recopositing)。
每次浏览器需要创建一个新的帧,合成器就需要draw。这里drawing是指合成器将层合成为最终的屏幕画面。
GPU是干啥的?
GPU是如何发挥作用的呢?合成器会使用GPU来执行它的drawing的步骤。这和老的软件渲染模型有显著的区别,在老的模型中,Render进程将页面内容的位图(bitmap)通过IPC(进程间通信)和共享内存的方式来传给浏览器进程去呈现。
在硬件加速体系结构中,合成由GPU负责,GPU通过调用平台特定的3D API(windows是D3D,其他是GL)来实现。合成器本质上也是使用GPU将页面的矩形区域(比如,相对于视口且根据layer树的优先级定位的所有合成层)draw成一个位图,也就是最终的屏幕图像。
GPU进程
首先我们需要了解Render进程如何传递命令给GPU的。在chrome多进程模型中,有一个专门的进程负责这个任务:GPU进程。GPU进程的存在主要是因为安全原因。需要注意的是,android是个例外,Chrom会使用内置的GPU实现作为浏览器主进程的一个线程来运行。当然android上的GPU线程和其他平台的GPU进程的行为是一致的。
受沙盒的限制,Render进程无法直接调用操作系统(GL/D3D)提供的3D API。因此,我们使用一个独立的进程访问,也就是GPU进程。而GPU进程也是专门被设计用来访问在沙箱或者更严格的Native Client中的系统3D API的。GPU进程的工作模式是一种client-server模式,原理如下:
- 客户端(运行在Render进程或者NaCl模块中的代码),会系列化调用命令,并把他们放到环形缓冲区(命令缓冲区command buffer)中,存储在由客户端和服务端共享的内存中。
- 服务端(在允许访问平台3D API的低限制级别的沙盒中运行的GPU进程),会从共享内存中拾取序列化的命令,解析他们,并执行相应的图形调用。
如下图:
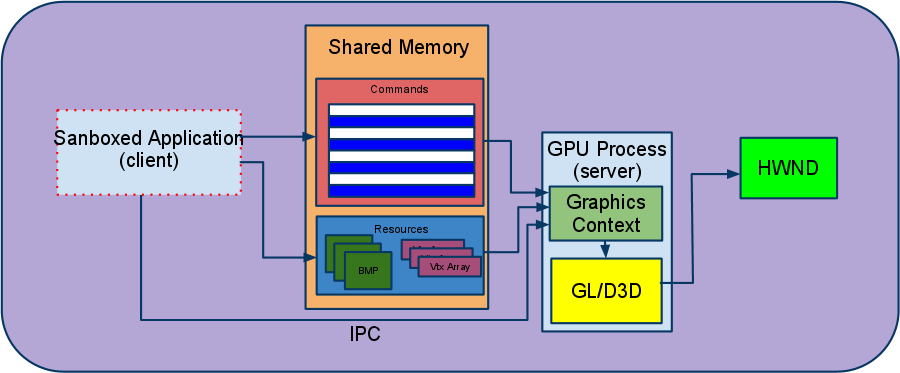
命令缓冲区(The Command Buffer)
The commands accepted by the GPU process are patterned closely after the GL ES 2.0 API (for example there’s a command corresponding to glClear, one to glDrawArrays, etc).因为大部分的GL调用没有返回值,客户端和服务端的工作方式基本上是异步的,而这种方式的性能会比较低。所以客户端和服务端就需要进行一些必要的同步,比如客户端通知服务端进行一些额外的工作,这种同步是通过IPC(Inter-Process Communication,进程间通信)机制实现的。
从客户端的角度来说,应用程序可以直接将命令写入命令缓冲区,或者通过客户端的库(处理序列化的)来使用GL ES 2.0 API。为方便起见,合成器和WebGL都是使用客户端库–GL ES。在服务端,命令会被转化成对OpenGL或者Direct3D的调用。
资源共享与同步(Resource Sharing & Synchronization)
除了为命令缓冲区提供存储,Chrome还使用共享内存在客户端(Render进程)和服务端(GPU进程)间传递较大的资源(比如:纹理texture[5]的位图、顶点数组等等)。
还有一个被称为mailbox的结构,提供了一种在命令缓冲区和纹理生命周期管理之间共享纹理的方式。mailbox是一个简单的字符串标识符,用来标示纹理的id,之后可以使用这个纹理id的别名来访问纹理。每一个被标示的纹理id代表了一个底层真正的纹理,删除了纹理id,那么真正的纹理也会被销毁。
Sync points提供一种不阻塞的同步方式,可以使命令缓冲区之间通过mailbox共享纹理。在命令区A上插入一个sync point,同时将命令区B上的sync point处于“等待wait”状态,这样可以保证,之后插入到B中得命令在A插入sync point前的命令执行完成前,是不会得到执行的。
命令缓冲区复用(Command Buffer Multiplexing)
现在,Chrome中,每一个浏览器实例、Render进程的所有服务请求以及任何的插件进程都会使用唯一的一个GPU进程。GPU进程可以在多个命令缓冲区之间复用,并且每一个命令缓冲区都有一个自己的渲染上下文。
每个合成器都有多个GL源,比如WebGL Canvas元素就可以直接产生GL命令流。层(由GPU直接创建内容的层)的合成流程如下:层会render进纹理中(使用Frame Buffer对象),当render GraphicsLayer时,合成器上下文可以抓取和使用这些纹理。值得注意的是,为了能让合成器的GL上下文访问到由屏幕外的GL上下文(比如被其他GraphicsLayer的FBO使用的GL上下文)产生的纹理,所有GPU进程使用的GL上下文都可以共享资源。
体系结构如下图所示:
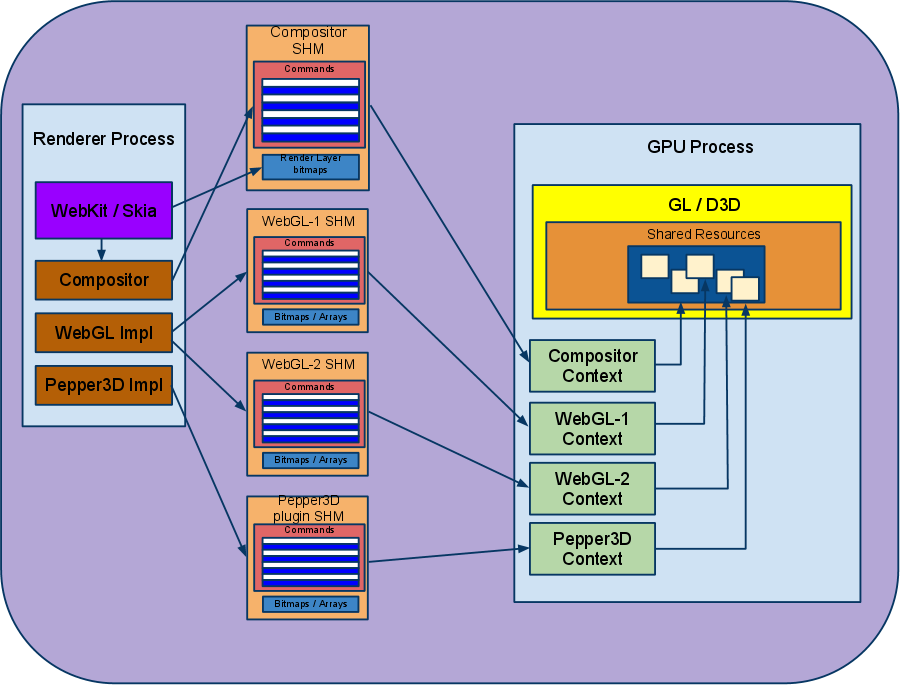
总结
GPU进程体系有如下的好处:
- 安全:render的逻辑大部分在沙盒渲染进程中,平台3D API的访问权限只对GPU进程开放。
- 鲁棒:GPU进程档掉并不会使浏览器挂掉。
- 一致性:作为浏览器渲染API的OpenGL ES 2.0是标准化的,跨平台的。
- 并行:Render进程可以快速 的将命令发给命令缓冲区,并且返回到CPU密集的render活动中,留给GPU进程去处理这些命令。我们可以充分利用多内核机器上的GPU进程和CPU进程。
接下来,我们将介绍合成器是如何产生GL命令和资源的。
Part 3:合成线程(The Threaded Compositor)
合成器是在GL ES 2.0客户端库基础上实现的,GL ES 2.0会使用之前提到的方法将图形调用代理到GPU进程中。当页面通过合成器渲染时,它的像素点会通过GPU进程直接draw(draw != paint)进窗口的backbuffer。
合成器的体系结构随时间而演变:最初,它在Renderer主线程中,然后转移到了自己的线程中(也就是所谓的合成线程),当发生paint(也就是所谓的impl-side painting)时,承担了排版(orchestrating)任务。
理论上来说,线程化的合成器,应该是从主线程中获取足够的信息,然后独立的产生帧,用以响应用户输入。实际上,这意味着,它要根据视口当前位置的层的区域来备份cc layer树和SkPicture。
Recording: Painting from Blink’s Perspective
interest area表示SkPictures记录的视口的范围区域。当DOM发生变化时(比如一些元素的样式同之前主线程中的帧不同,且已经invalidate(需要repaint)),Blink引擎通过将intereat area放入 SkPicture-backed GraphicsContext中,来paint这些invalidated的层的区域。这实际上并不产生新的像素,而是产生一个display list,里面存储这产生这些新像素的Skia命令。之后这个display list可以在合成器中使用,来产生新的像素。
切换到合成线程(The Commit: Handoff to the Compositor Thread)
线程化的合成器的一个关键的特性是他可以在主线程状态的副本上进行操作,这样就可以无需向主线程请求,来产生帧。合成器有两部分:主线程部分和impl部分(合成线程的一部分)。主线程有一个LayerTreeHost(是layer tree的副本),impl线程有一个LayerTreeHostImpl(是layer tree的副本)。
理论上,这两个layer tree是完全分开的,并且合成(impl)线程可以在不与主线程有任何交互的情况下产生帧。这意味着主线程可以专注于运行javascript,而合成器依然可以redraw之前提交给GPU的内容而不被阻塞。
为了产生新的帧,合成线程需要知道如何改变它的状态(比如更新scroll事件对应的层的变换)。因此,一些输入事件(比如scroll)会首先从浏览器进程转移到合成器,然后从合成器转交给Renderer主线程。通过控制输入和输出,合成器可以保证对用户输入进行视觉响应。除了scroll滚动,合成器执行一些页面更新(目前只有CSS 动画和CSS滤镜)而不需要请求Blink引擎进行repaint。
主线程的LayerTreeHost和impl线程的LayerTreeHostImpl,这两个layer tree由被称为commit的消息来保持同步,这些消息由合成器的调度程序(cc/trees/thread_proxy.cc中)进行管理和调度。commit会将主线程的状态(包括更新过的layer tree和新的SkPicture记录等等)传递给合成线程。这种同步是会阻塞主线程的。这是产生特定帧过程中,有主线程参与的最后一步。
将合成器运行在独立的线程中,可以让合成器用layer tree的副本来更新层的transform hierarchy,而不需要涉及到主线程。但是主线程还是需要知道一些信息比如滚动偏移量等等,(这样javascript才可以知道页面滚动到哪)。因此,commit消息还负责将合成线程中得layer tree更新到主线程中。
有趣的是,这种体系结构导致了javascript的touch事件处理程序(调用preventDefault())可以阻止滚动,而scroll事件的处理程序却不可以。如果javascript可能要取消touch事件,那么合成器在请求javascript(运行在主线程中)前是不会滚动页面的。另一方面,scroll事件不能被阻止并且会异步的传给javascript,因此,合成线程会立刻开始滚动,而不管主线程是否立刻处理滚动事件。
激活树(Tree Activation)
当合成线程从主线程那里得到一个新的layer tree以后,合成线程会检查树中的invalid区域,并且换重新栅格化树中得layer。在此期间,active tree会保存之前在合成线程中老的layer tree,而pending tree是新的要被栅格化的树。
为保证显示内容的一致性,pending tree只有它的可见的(比如出现在视口中)高分辨率的内容完全栅格化以后才能被激活(avtivate)。从一个当前active tree切换到一个ready的pending tree的过程成为activation(激活)。等待栅格化内容准备的过程意味着用户通常可以看到一些可能过时的内容。如果没有内容可用,Chrome会显示通过GL着色器产生的空白或者盘格(checkerboard)图案来代替。
值得注意的是,因为Chrome只记录在interest area中的layer区域的SkPicture,所以有可能会滚动出active tree的栅格区域。如果用户朝着一个unrecorded区域滚动,合成器会请求主线程record和commit额外内容(additional content),但是,如果新的内容没有及时的recode、commit、栅格化(rasterize)以激活,用户会滚动到一个checkerboard区域。
为了减轻上述出现checkerboard的情况,Chrome可以在栅格化pending tree高分辨率内容之前先快速的将其栅格化为低分辨率的内容。持有可以被视口所用的低分辨率的内容的pending tree,如果它的持有的内容比当前屏幕上的好(比如,相应的active tree没有针对当前视口的完全栅格化的内容时),那么这个pending tree就会被激活。切片(tile)管理程序(下文会讲到)决定什么内容在什么时候栅格化。
这种体系结构将栅格化从帧生产流程中剥离出来。它促进了很多提升图形系统响应速度的技术。图片的解码和缩放操作是异步的,而这在之前是在pain过程中执行的昂贵的主线程操作。
切片(Tiling)
栅格化整个layer十分浪费CPU时间(paint操作的时间)和内存(RAM for any software bitmaps the layer needs; VRAM for the texture storage)。合成器会将大部分web content layer分解为切片(tile),并且在这些切片的基础上栅格化层。
Web content layer tiles根据一系列因素来确定优先级,包括,靠近视口的程度和在屏幕上显示的预估时间。GPU内存会根据切片的优先级分配给切片,之后切换会根据优先级,栅格化,并存储到可用的内存空间中。查阅 Tile Prioritization Design Doc了解更多。
值得注意的是,对于那些内容已经驻留在GPU上的层(比如accelerated video和WebGL),就不需要切片了。
栅格化(Rasterization): Painting from cc/Skia’s perspective
合成线程中的SkPicture转换成GPU上的位图有两种方式:
- 由Skia的software rasterizer paint进位图中,然后作为纹理上传到GPU中
- 由Skia的 OpenGL backend (Ganesh)直接paint进GPU上的纹理中
- 对于Ganesh-rasterized layers,the SkPicture is played back with Ganesh 然后所得的GL命令流会通过命令缓冲区交给GPU进程处理。当合成器决定栅格化切片时,会立刻产生GL命令,同时切片会捆绑在一起处理,防止栅格切片时,GPU的过高消耗。看这里GPU accelerated rasterization design doc了解更多。
对于software-rasterized的层来说,会paint进共享内存(由Render进程和GPU进程)里的位图中。位图会通过之前介绍的资源转移机制交给GPU进行处理。由于software rasterization的性能代价十分昂贵,所以rasterization不会在合成线程中进行(否则它会阻塞active tree的新一帧的drawing),而是在compositor raster worker线程中进行。多个raster worker 线程可用于加快software rasterization。最终的切片会作为纹理上传到GPU。
位图的纹理上传受平台的内存带宽限制。纹理上传会影响software-rasterized layer的性能,并且会影响需要hardware rasterizer(硬件栅格化)的位图(比如image data或者CPU-rendered masks)的上传。过去,chrome有许多不同的纹理上传机制,但是最成功的还是异步上传(asynchronous uploader),这种机制,将上传放在GPU进程的一个worker线程中(对于android来说,是在浏览器进程的一个additional线程中),这样,其他操作就不会阻塞可能长时间的纹理上传。
有一个彻底解决纹理上传问题的方法,就是在unified memory architecture设备上使用CPU和GPU共享的zero-copy buffers。Chrome目前还没有使用,不过未来会得。更多看这里GpuMemoryBuffer design doc
Drawing on the GPU, Tiling, and Quads
一旦所有的纹理填充完毕,那么接下来就简单了,对layer的层次结构做深度优先遍历,然后发出GL命令,将每一个layer的纹理draw进frame buffer(帧缓冲器)中。
在屏幕上draw一个层,其实就是draw它的每一个切片。切片被表示成quad(简单的四边形,比如矩形),这些quads绘制填充的是给定层的内容的一个分区。合成器会生成quads和一组render passes(渲染通道,存储quads列表的简单的数据结构)。drawing的实际GL命令的产生同quads的产生是分离的(详见cc/output/gl_renderer.cc)。drawing quads或多或少要为每一个render pass建立一个viewport和transform,并且要绘制(draw)rander pass的quad list中的每一个quad。
Varied Scale Factors(多种比例因素)
impl-side painting的一个显著的优点就是,合成器可以以任意的比例reraster(栅格化)已存在的SkPictures。这在两种情形下十分有用:双指缩放和在fast fling(快速滚动)期间产生低分辨率切片。
合成器会拦截pinch/zoom的输入事件,并且在GPU上按适当比例缩放已经栅格化(按最合适的分辨率)的切片。每当这个新的切片准备好了(被栅格化且上传),通过激活pending tree和提高pinch/zoom的屏幕的分辨率,这些切片会被swap in。
当由software进行栅格化时,如果在滚动过程中,高分辨率的切片没有准备好,那么compositor也会试图快速的产生低分辨率的切片(对paint负担较小),并且先展示低分辨率的这些。这就是为什么一些页面在快速滚动过程中看起来会模糊—合成器将低分辨的切片展示到了屏幕上。
附录
The Software Compositor(软件合成器)
在某些情况下,硬件合成是不可行的,比如一个设备的图形驱动被加入了黑名单或者压根就没有GPU。对于这些情况,另一种替代GL renderer的实现称为SoftwareRenderer(详见src/cc/output/software_renderer)。总的来说,Chrom除了需要访问GPU的那些操作,software和硬件上的功能大体相同,但在实现上有如下几个关键的不同点:
- 它会把quad留存在系统内存中,并以共享内存的形式传递他们,而不是将quad作为纹理上传到GPU中
- software renderer使用Skia的software rasterizer来复制内容纹理(content texture)到backbuffer中,并且会执行一些必要的matrix math和clipping。而不是使用GL。
术语表
- [1] compositing:将RenderLayer的纹理(texture)合成为最终屏幕上的图片
- [2] drawing:将像素点绘制到屏幕上(将最终的屏幕画面放到屏幕上)的render阶段
- [3] painting:RenderObjects调用GraphicsContext API生成相应的视觉展现的render阶段。生成元素呈现的像素,例如,一个有着灰色背景,有文字的元素,当浏览器paint它时,是决定哪些像素填充背景,哪些像素填充文字,然后浏览器将这些像素存入位图(bitmap)中。
- [4] bitmap:内存或显存中一组像素值
- [5] texture:应用于GPU 3D模型上的位图(bitmap)
- [6] invalidation:标记为dirty的文档区域,一般表示该区域需要repainting。样式系统(style system)也有相同的概念。
- [7] rasterization:位图(backing up RenderLayers)填充(fill)的rendering阶段。当RenderObjects调用GraphicsContext时会立即发生rasterization。或者当我们使用SkPicture record来painting且使用SkPicture playback来rasterization时,会发生rasterization。
- [8] texture quad:应用于四个点多边形(比如矩形)的这种简单模型的纹理。
- [9] backbuffer:when double-buffering, the screen buffer that’s rendered into, not the one that’s currently being displayed
- [10] frontbuffer:when double-buffering, the screen buffer that’s currently being displayed, not the one that’s currently being rendered into
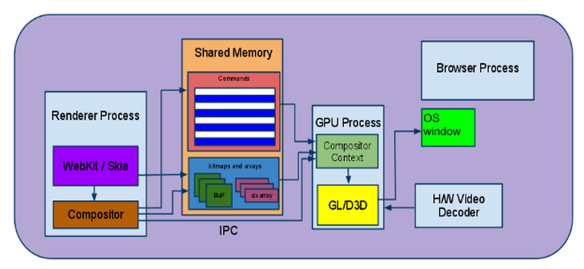
From WebKit to the Screen
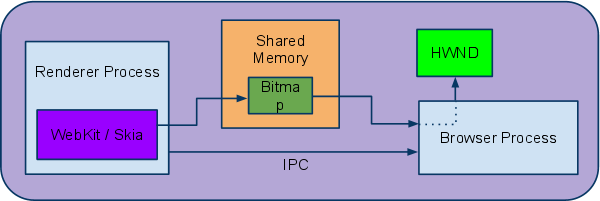
一旦所有的RenderLayers都paint进共享位图中,依然需要将位图放到屏幕上。在chrom中,位图驻留在共享内存中并且通过IPC传给浏览器进程。浏览器进程会通过操作系统的windowing APIs(比如windows的相关HWND),将位图draw到相应的选项卡或窗口中
本翻译来自地址:http://wibuder.com/blog/2014/11/03/yi-gpu-accelerated-compositing-in-chrome(gpuhe-cheng-jia-su-)/
摘过来主要是为了保存,以下为原翻译作者总结,挪到后面感觉合适点。
先来简单的总结下
硬件(GPU)加速加速的是啥?是层的合成(layer composite),所以有些说使用translate3D打开硬件加速的说法是不恰当的,GPU加速是一直在的(在有GPU且设备的图形驱动可用的情况下),在chrome中,使用translate3D其实是使该元素拥有独立的GraphicsLayer,那拥有独立的GraphicsLayer有啥好处呢?简单来说有如下几点:
- 每个GraphicsLayer都有一个GraphicsContext,GraphicsContext会输出该层的位图,交由GPU合成,比CPU要快
- 当需要repaint时,只需要repaint自己,不会影响到其他的GraphicsLayer。repaint完之后,只需要通过GPU同其他层合并下(composite layers)
- 对于CSS动画,不需要repaint
下面简单介绍下chrome的渲染原理,详细了解可看下面译文或者直接读原文:
在chrome中为render服务的有4种树形结构,我们熟知的DOM树是其中之一,其他的三个分别是:
RenderObject Tree
由RenderObject构成,RenderObject同DOM树中得Node节点一一对应,RenderObject知道如何去paint(paint != draw)其对应的Node。
RenderLayers Tree
由RenderLayer构成,RenderLayer同RenderObject是一对多的关系,满足如下条件的RenderObject拥有新的RenderLayer,而其他的RenderObject就和它的第一个拥有独立RenderLayer的父元素公用一个RenderLayer。
- 页面的根节点的RenderObject
- 有明确的CSS定位属性(relative,absolute或者transform)
- 是透明的
- 有CSS overflow、CSS alpha遮罩(alpha mash)或者CSS reflection
- 有CSS 滤镜(fliter)
- 3D环境或者2D加速环境的canvas元素对应的RenderObject
- video元素对应的RenderObject
GraphicsLayers Tree
由GraphicsLayer构成,GraphicsLayer同RenderLayer的关系和RenderLayer同RenderObject的关系是一样的。满足如下条件的RenderLayer会拥有新的GraphicsLayer。
- 有3D或者perspective transform的CSS属性的层
- 使用加速视频解码的video元素的层
- 3D或者加速2D环境下的canvas元素的层
- 插件,比如flash(Layer is used for a composited plugin)
- 对opacity和transform应用了CSS动画的层
- 使用了加速CSS滤镜(filters)的层
- 有合成层后代的层
- 同合成层重叠,且在该合成层上面(z-index)渲染的层
每个GraphicsLayer都有一个GraphicsContext,GraphicsContext会负责输出该层的位图,位图是存储在共享内存中,作为纹理上传到GPU中,最后由GPU将多个位图进行合成,然后draw到屏幕上。
需要注意的是
GraphicsLayer是消耗内存资源的
所以说,对于像translate3D这样的hack不要过度使用,尤其是在手机上,大部分手机的显存和内存是共享的,GraphicsLayer过多导致内存占用过多的话,会使手机变卡的。
在chrome为渲染服务的有两个进程:Render进程和GPU进程。GPU进程负责Render进程和GPU之间的命令的传递,Render进程包括主线程和合成线程,在chrome中,paint和composite放在了合成线程中。