最近在学习正则,感觉正则的水很深,做了点笔记,当是入门吧。我会从以下几点来入门:什么是正则、正则的基本语法、正则的匹配原理。如果有基础,可以直接跳过前两点,直接看“RegExp的匹配原理”。
什么是RegExp
什么是正则呢?正则就是由一些普通字符和元字符组成的,用来匹配(字符匹配和位置匹配)我们想要获得的字符串。
普通字符&元字符
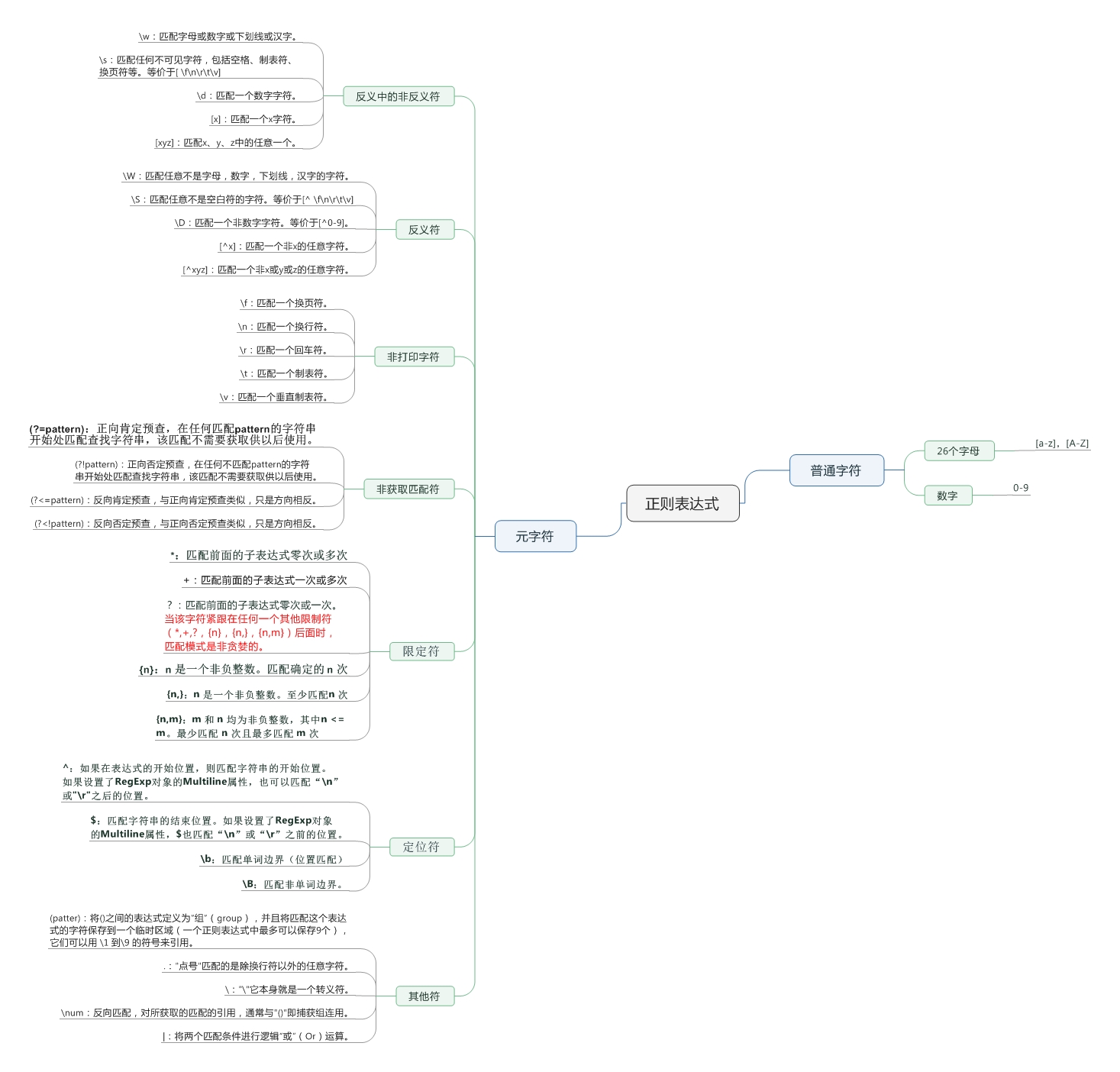
运算符优先级
正则表达式从左到右进行计算,并遵循优先级顺序。
相同优先级的从左到右进行运算,不同优先级的运算先高后低。
| 运算符 | 描述 |
|---|---|
| \ | 转义 |
| (), (?:), (?=), [] | 圆括号和方括号 |
| *, +, ?, {n}, {n,}, {n,m} | 限定符 |
| ^, $, \任何元字符、任何字符 | 定位点和序列(即:位置和顺序) |
| \ | “或”操作字符 |
注意事项:
对于那些有特殊意义的元字符,如果要匹配的是字符的本身而非元字符,则要用转义字符来将它装换过来。下面列举出这些特殊字符:
$、()、、+、.、[]、?、\、^、{}、|
将这些转义:
\$、()、\、+、.、[]、\?、\、\^、{}、|
RegExp的基本语法
创建表达式
创建正则表达式提供了两种方法:一种是采用new运算符,另一个是采用字面量方式。
- 采用new运算符
1 | var box = new RegExp('box'); //第一个参数字符串 |
- 采用字面量方式
1 | var box = /box/; //直接用两个反斜杠 |
模式修饰符的可选参数表
| 参数 | 含义 |
|---|---|
| i | 忽略大小写 |
| g | 全局匹配 |
| m | 多行匹配 |
测试正则表达式
RegExp对象包含两个方法:test()和exec(),功能基本相似,用于测试字符串匹配。
| 方 法 | 功 能 |
|---|---|
| test | 字符串中测试模式匹配,返回true或false |
| exec | 在字符串中执行匹配搜索,返回结果数组 |
1 | /*使用new运算符的test方法示例*/ |
1 | /*使用字面量方式的test方法示例*/ |
1 | /*使用一条语句实现正则匹配*/ |
1 | /*使用exec返回匹配数组*/ |
RegExp的匹配原理
正则表达式引擎
正则引擎大体上可分为不同的两类:
DFA(确定型有穷自动机)和NFA(非确定型有穷自动机),而NFA又基本上可以分为传统型NFA和POSIX NFA。
DFA:文本串去比较正则式,看到一个子正则式,就把可能的匹配串全标注出来,然后再看正则式的下一个部分,根据新的匹配结果更新标注。
NFA:正则式去比文本,拿到一个字符,就把它跟正则式比较,匹配就记下来,然后接着往下匹配。一旦不匹配,就把刚拿的这个字符丢掉,一个个的丢掉,直到回到上一次匹配的地方。
引擎间的区别:
| 引擎 | 区别 | 使用语言 |
|---|---|---|
| DFA | 不需要回溯,所以匹配快速,但不支持捕获组,所以也就不支持反向引用和$number这种引用方式 | 目前使用DFA引擎的语言和工具主要有awk、egrep 和 lex |
| POSIX NFA | 主要指符合POSIX标准的NFA引擎,它的特点主要是在找到最左侧最长匹配之前,它将继续回溯。同DFA一样,非贪婪模式或者说忽略优先量词 | 无 |
| 传统NFA | 支持:捕获组、反向引用和$number引用方式;环视(?<=…)、(?<!…)、(?=…)、(?!…)忽略优化量词(??、?、+?、{m,n}?、{m,}?),或者有的文章叫做非贪婪模式;占有优先量词(?+、+、++、{m,n}+、{m,}+,目前仅Java和PCRE支持)固化分组(?>…) | 大多数语言和工具使用的是传统型的NFA引擎 |
从表中可以看出,在JavaScript的世界里,我们用到的引擎只有传统NFA,其他的则不兼容。因此,下面的内容将全部是传统的NFA引擎机制。
引擎区别的例子:
1 | 正则式:/perl | perlman/ |

如果是NFA,则以正则式为导向,手里捏着正则式,眼睛看着文本,一个字符一个字符的吃,吃完’perl’以后,跟第一个子正则式/perl/已经匹配上了,于是记录在案,往下再看,吃进一个’m’,这下糟了,跟子式/perl/不匹配了,于是把m吐出来,向上汇报说成功匹配’perl’,不再关心其他,也不尝试后面那个子正则式/perlman/,自然也就看不到那个更好的答案了。
如果是DFA,它是以文本为导向,手里捏着文本,眼睛看着正则式,一口一口的吃。吃到/p/,就在手里的’p’上打一个钩,记上一笔,说这个字符已经匹配上了,然后往下吃。当看到/perl/之后,DFA不会停,会尝试再吃一口。这时候,第一个子正则式已经山穷水尽了,没得吃了,于是就甩掉它,去吃第二个子正则式的/m/。这一吃好了,因为又匹配上了,于是接着往下吃。直到把正则式吃完,成功匹配了’perlman’。
预备知识
字符串的组成
占有字符和零宽度
占有字符:若子表达式匹配到的是字符内容,而非位置,并被保存到最终的匹配结果中,那么就认为这个子表达式是占有字符的。
零宽度:如果子表达式匹配的仅仅是位置,或者匹配的内容并不保存到最终的匹配结果中,那么就认为这个子表达式是零宽度的。
注意:一个字符,同一时间只能由一个子表达式匹配
一个位置,可以同时由多个零宽度的子表达式匹配
RegExp简单匹配过程
含有匹配优先量词——匹配成功
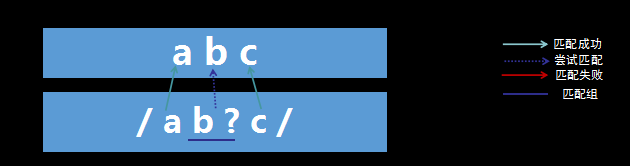
过程解析:
- 首先由字符“a”取得控制权,从位置0开始匹配,由“a”来匹配“a”,匹配成功。
- 控制权交给字符”b?”;先尝试进行匹配,由“b?”来匹配“b”,同时记录一个备选状态,匹配成功。
- 控制权交给“c”;由“c”来匹配“c”,匹配成功,记录的备选状态丢弃。
含有匹配优先量词——匹配失败
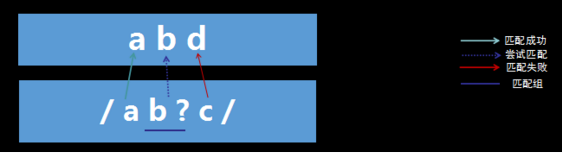
过程解析:
- 首先由字符“a”取得控制权,从位置0开始匹配,由“a”来匹配“a”,匹配成功。
- 控制权交给字符”b?”;先尝试进行匹配,由“b?”来匹配“b”,同时记录一个备选状态,匹配成功。
- 控制权交给“c”;由“c”来匹配“d”,匹配失败,此时进行回溯,找到记录的备选状态,“b?”忽略匹配,即“b?”不匹配“b”,让出控制权。
- 控制权交给“c”;由“c”来匹配“b”,匹配失败。此时第一轮匹配尝试失败。
含有忽略优先量词的匹配——匹配成功
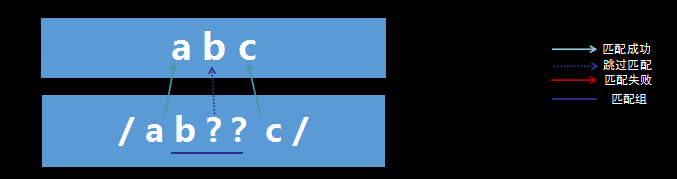
过程解析:
- 首先由字符“a”取得控制权,从位置0开始匹配,由“a”来匹配“a”,匹配成功。
- 控制权交给字符“b??”;先尝试忽略匹配,即“b??”不进行匹配,同时记录一个备选状态。
- 控制权交给“c”;由“c”来匹配“b”,匹配失败。
- 此时进行回溯,找到记录的备选状态,“b??”尝试匹配,即“b??”来匹配“b”,匹配成功。
- 把控制权交给“c”;由“c”来匹配“c”,匹配成功。
零宽度匹配
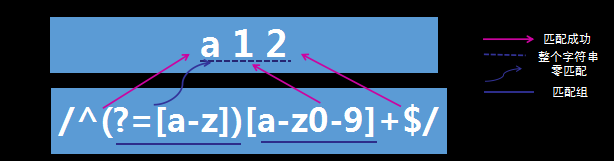
过程解析:
- 首先由元字符“^”取得控制权,从位置0开始匹配,“^”匹配的就是开始位置“位置0”,匹配成功。
- 控制权交给顺序环视“(?=[a-z])”,“(?=[a-z])”要求它所在位置右侧必须是字母才能匹配成功,同一个位置可以同时由多个零宽度子表达式匹配,所以它也是从位置0尝试进行匹配,位置0的右侧是字符“a”,符合要求,匹配成功。
- 控制权交给“[a-z0-9]+”,因为“(?=[a-z])”只匹配,并不将匹配到的内容保存到最后结果,并且“(?=[a-z])”匹配成功的位置是位置0,所以“[a-z0-9]+”也是从位置0开始尝试匹配的,“[a-z0-9]+”首先尝试匹配“a”,匹配成功,继续尝试匹配,可以成功匹配接下来的“1”和“2”,此时已经匹配到位置3,位置3的右侧已没有字符。
- 控制权交给“$”;它从位置3开始尝试匹配,它匹配的是结束位置,也就是“位置3”,匹配成功。
回溯
NFA引擎最重要的性质是,它会依次处理各个子表达式或组成元素,遇到需要在两个可能成功的可能中进行选择的时候,它会选择其一,同时记住另一个,以备稍后可能的需要。
需要做出选择的情形包括量词(决定是否尝试另一次匹配)和多选结构(决定选择哪个多选分支,留下哪个稍后尝试)。
不论选择那一种途径,如果它能匹配成功,而且正则表达式的余下部分也成功了,匹配即告完成。如果正则表达式中余下的部分最终匹配失败,引擎会知道需要回溯到之前做出选择的地方,选择其他的备用分支继续尝试。这样,引擎最终会尝试表达式的所有可能途径(或者是匹配完成之前需要的所有途径)。
回溯形象点讲,就像是在道路的每个分岔口留下一小堆面包屑。如果走了死路,就可以照原路返回,直到遇见面包屑标示的尚未尝试过的道路。如果那条路也走不通,你可以继续返回,找到下一堆面包屑,如此重复,直到找到出路,或者走完所有没有尝试过的路。
回溯两要点
多个选择时,哪个分支应首先选择
若需在“进行尝试”和“跳过尝试”之间选择,对于匹配优先量词,引擎会优先选择“进行尝试”。对于忽略优先量词,引擎会优先选“跳过尝试”。回溯进行时,应选哪个保存状态
距离当前最近的选项就是当本地失败强制回溯时返回的。使用原则是LIFO(后进先出)。
回溯小例子
1 | 字符串:‘hot tonic tonight!’ |
过程解析:“t”字符无法匹配“h”,所以第0个位置失败,一直到第5个位置,“t”匹配“t”,成功。第6个位置“o”匹配“o”,成功。开始3个分支的匹配,分别是/nite/、/knight/、/night/,由于没有优先匹配量词,所以按从左到右的顺序匹配。匹配第一个分支/nite/,“n”匹配“n”,成功。直到”t”匹配“c”,失败。但是此时并不意味着整个表达式失败,因为还有其他的分支(之前预留的面包屑)。第二个分支开始匹配,匹配又从第7个位置开始,但是很快就失败了,“k”与“n”不匹配。第三个分支开始匹配,明显成功,则整个表达式匹配成功。如果第三个分支也失败的话,就表明整个表达式匹配失败。
备用状态
用NFA正则表达式的术语来说,那些面包屑相当于“备用状态”。它们用来标记:在需要的时候,匹配可以从这里重新开始尝试。
备用状态保存了两个位置:
- 正则表达式中的位置
- 未尝试的分支在字符串中的位置
备用状态例子
当前是“a”已经匹配完了的状态

轮到了“b?”,引擎决定尝试匹配,但为了确保这个尝试最终失败后能够恢复,引擎把“b?”添加到备用状态中,稍后引擎还可以从正则表达式“b?”之后,字符串”b”之前(当前位置)匹配,即“b?”没有匹配,“?”可以这样。

最后引擎放下面包屑后,继续向前,检测“b”,在例子中可以匹配,所以新状态变成下面的,最终“c”也匹配成功,整个匹配成功,所以备用状态不需要了,便不再保存它们。

环视匹配
- 顺序肯定环视(?=Expression)
当子表达式Expression匹配成功时,(?=Expression)匹配成功,并报告(?=Expression)匹配当前位置成功。 - 顺序否定环视(?!Expression)
当子表达式Expression匹配成功时,(?!Expression)匹配失败;当子表达式Expression匹配失败时,(?!Expression)匹配成功,并报告(?!Expression)匹配当前位置成功;
环视匹配其实有四类:顺序肯定环视、顺序否定环视、逆序肯定环视、逆序否定环视,只是后两者在JavaScript的环境中不支持,所以不讲。
环视的例子在讲完捕获组之后,结合捕获组一起使用。
捕获组
什么是捕获组
捕获组就是把正则表达式中子表达式匹配的内容,保存到内存中以数字编号或显式命名的组里,方便后面引用。当然,这种引用既可以是在正则表达式内部,也可以是在正则表达式外部。
捕获组有两种形式,一种是普通捕获组,另一种是命名捕获组,通常所说的捕获组指的是普通捕获组。
语法如下:
普通捕获组:(Expression)
命名捕获组:(?
普通捕获组在大多数支持正则表达式的语言或工具中都是支持的,而命名捕获组目前只有.NET、PHP、Python等部分语言支持。
- 捕获组编号规则
编号规则指的是以数字为捕获组进行编号的规则。- 普通捕获组编号规则
若没有显式为捕获组命名,即没有使用命名捕获组,那么需要按数字顺序来访问所有捕获组。在只有普通捕获组的情况下,捕获组的编号是按照“(”出现的顺序,从左到右,从1开始进行编号的 。 - 命名捕获组编号规则
命名捕获组通过显式命名,可以通过组名方便的访问到指定的组,而不需要去一个个的数编号,同时避免了在正则表达式扩展过程中,捕获组的增加或减少对引用结果导致的不可控。
- 普通捕获组编号规则
不过容易忽略的是,命名捕获组也参与了编号的,在只有命名捕获组的情况下,捕获组的编号也是按照“(”出现的顺序,从左到右,从1开始进行编号的 。
普通捕获组编号规则 –例子1
正则表达式:(\d{4})-(\d{2}-(\d\d))
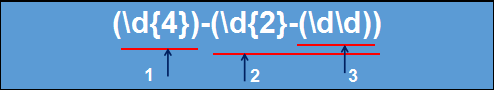
命名捕获组编号规则 –例子
1 | 正则表达式:(?<year>\d{4})-(?<date>\d{2}-(?<day>\d\d)) |

捕获组的引用
对捕获组的引用一般有以下几种:
1) 正则表达式中,对前面捕获组捕获的内容进行引用,称为反向引用;
2) 正则表达式中,(?(name)yes|no)的条件判断结构;
3) 在程序中,对捕获组捕获内容的引用。
反向引用
捕获组捕获到的内容,不仅可以在正则表达式外部通过程序进行引用,也可以在正则表达式内部进行引用,这种引用方式就是反向引用。
反向引用的作用通常是用来查找或限定重复,限定指定标识配对出现等等。
对于普通捕获组和命名捕获组的引用,语法如下:
- 普通捕获组反向引用:\k
,通常简写为\number;或$number(这个表达是在程序中引用的) - 命名捕获组反向引用:\k
或者\k’name’
普通捕获组反向引用中number是十进制的数字,即捕获组的编号;命名捕获组反向引用中的name为命名捕获组的组名。
捕获和反向引用的例子
例一:
// 向一个字符串中每三个字符插入一个空格,在程序中引用
var str = '1234abcde';
alert(str.replace(/(.{3})/g),'$1 '); //123 4ab cde
例二
//对前面字符的引用
var pattern = /(\w)\1{4,}/g;
var str = '2234cc 5555 66666';
alert(pattern.exec(str));//66666,前面5个“6”是匹配结果,后面的“6”是1号捕获组(\w)的匹配结果
环视与捕获组的例子
给数字加上千分号:
var str = '121212321';
var reg = /(\d)(?=(\d{3})+(?!\d))/g;
alert(str.replace(reg,'$1,')); //121,212,321
过程分析
- 总共有三个分组,分别是(\d)、(?=(\d{3})+(?!\d))、(?!\d),首选$1获得控制权,匹配“1”,匹配成功,返回结果“1”,引擎继续向下转动。
- \$1把控制权交给\$2,由\$2去匹配一个和多个的3个数字组,匹配了“212”、“123”,最后的“21”没有3个数字,所以不匹配,匹配成功,但它并
不返回匹配成功的结果“212”和“123”(因为它是环视匹配),只是当做一个满足条件,引擎继续向下转动。 - \$2把控制权交给\$3,由\$3去匹配最后的两个数字“21”,“2”不是最后的结尾位置,匹配失败,第一轮的匹配失败,将进行第二轮的匹配。
- 知道\$1匹配到第二个“1”,匹配成功,返回结果“第二个1”,引擎继续向下转动。然后\$2匹配“212”和“321”,匹配成功,但不返回结果,引擎继续向下转动。$3匹配结尾位置,这一轮匹配成功,最终的到的结果是“
第二个1”。 - 一直往下匹配,最终结果是“第二个1”、“第三个2”、“第四个1”。